redis-stream
Redis Stream
何为 redis stream
Redis Stream 是 redis 5.0 版本引入的一种新数据类型,可以认为是一个消息队列,但是相比List实现的消息队列功能又更为强大。下面结合官方教程进行简单介绍。详细介绍可以参见这里。
Redis 安装
上面介绍说过,stream是5.0开始才有的特性,如果要使用stream,那么首先要先安装(或者升级)redis到5.0以后,这里我们可以从官网下载截止目前最新的版本5.0.7,如果官网下载速度慢,可以从这里下载。
我这里的环境是 OSX 10.15.2,其他linux系统理论上都可以使用,windows 未安装测试。
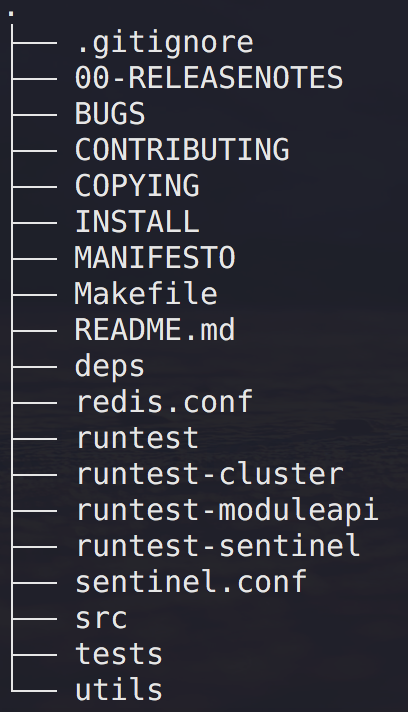
下载完成后解压 命令:tar -xvf redis-5.0.7.tar.gz 并得到 目录redis-5.0.7 结构如下:
执行命令cd redis-5.0.7 进入到目录内,执行命令 make 进行编译,当最后输出:
Hint: It’s a good idea to run ‘make test’ ;)
的时候,说明编译通过了,并且在 src 目录中会生成 redis-server 文件。
如果报错:
jemalloc/jemalloc.h: No such file or directory
进入 redis目录下的 dist目录执行 make hiredis lua jemalloc linenoise,然后 cd .. && make 再次编译。
执行 src/redis-server 启动redis,在另一个终端中输入 src/redic-cli 进入交互界面。
Stream 的使用
XADD 命令
XADD 命令可以在指定的一个stream中追加新的数据,主要用法如下:
XADD key ID field string [field string ...]
- key 要使用的 stream 的名字,可以随便起
- ID 要生成的id,可以自己指定,格式
1526919030474-55,使用-分隔,前后都是64bit的正整数,注意,后面插入的数据的id必须大于上次的id,比如 先插入1001-1,在插入1-1是不合法的。也可以使用*自动生成,当自动生成的时候,格式是:前部分是unix毫秒时间戳,后面是在这1ms内的序号(从0开始),一般来说都使用自动生成。 - field 和 string 是一对,必须成对出现,类似于map,field是key的名字,string 是值,只能使用string类型。只要成对,后面可以1到多个。
示例:
输入: XADD mystream * sensor-id 1234 temperature 19.8, 输出 "1576646561236-0"(类似结构,这个值是我执行时候的当前时间戳)
解释: 将 sensor-id 1234 temperature 19.8 追加到名为 mystream 的stream中,并且id使用自动生成。这个地方是模拟了一个传感器上报数据,传感器id是 1234, 当前温度 19.8。
类似的,我们可以再增加几条数据: XADD mystream * sensor-id 0001 temperature 10.1,XADD mystream * sensor-id 0002 temperature 20.1,同样输出一个自动生成的id。
XLEN 命令
XLEN 命令可以查看对应的 stream 的长度,也就是该stream内的元素个数;注意这里的元素是指通过 XADD 这个命令插入的消息,比如上面 XADD mystream * sensor-id 1234 temperature 19.8 sensor-id 1234 temperature 19.8 是一个元素。
基本用法:
XLEN key
key 就是要查看的 stream 的名字。
要查看上面我们插入的名为 mystream stream 的长度,则可以输入 XLEN mystream,输出的数字就是该stream当前长度。
XREAD 命令
XREAD 命令可以读取stream中的数据,基本用法如下:
XREAD [COUNT count] [BLOCK milliseconds] STREAMS key [key …] ID [ID …]
解释:
- XREAD 命令
- COUNT 一次性读取的数量,后面跟正整数
- BLOCK 读取的时候,如果没有符合条件消息,则进行阻塞等待的时间毫秒数,如果直到超时都没有收到新的消息就返回空,否则返回新的消息
- STREAMS 固定格式
- key stream 名字,可以指定1到多个stream读取
- ID 要开始过滤的消息ID,此 ID 和 XADD 命令产生的 ID 是同一个东西。注意,这里的过滤条件是 大于 ID。如果指定了多个stream,这里也要分别指定每个stream要开始的ID。
XREAD 举例
要读取上面我们添加到 stream
mystream的所有数据:1
XREAD streams mystream 0-0
过滤 ID
1576719377792-0以后的数据1
XREAD streams mystream 1576719377792-0
自定义返回的数据条数
上面的语句执行后会将整个 stream 内的数据都读取出来,为避免一次性读取出所有,我们可以
COUNT关键词来约束返回的条数,这个约束的是 最多返回的条数1
XREAD COUNT 1 streams mystream $
COUNT后面的数字是约束要返回的条数,这里我们指定为1,代表最多返回1条。 如果 stream 内有2条,但是指定COUNT 10,那么也是返回2条。要读取stream最新的消息
1
XREAD streams mystream $
注意,这里用
$这个特殊的 ID 来说明要读取的是最新的消息。这个示例会直接返回
(nil),因为没有加BLOCK是直接返回的,即使是没有数据。读取最新的消息,如果没有新消息则阻塞10s
1
XREAD BLOCK 10000 streams mystream $
BLOCK后面的数值 10000 是毫秒数。 如果在这个10s内没有新的数据流入,那么10s后输出(nil)
(10.15s)重新执行
XREAD BLOCK 10000 streams mystream $,并且在另一个终端中进入redis-cli交互,输入XADD mystream * sensor-id 1234 temperature 19.8则就会打印出刚才输入的内容。1
2
3
4
5
6
71) 1) "mystream"
2) 1) 1) "1576719377792-0"
2) 1) "sensor-id"
2) "1234"
3) "temperature"
4) "19.8"
(1.75s)
ID 兼容 XREAD 中 ID 只写前半部分的毫秒时间戳也是兼容的
XRANGE 命令
XRANGE 也是用于读取数据,但是可以指定 ID 区间,基本用法:
1 | XRANGE key start end [COUNT count] |
- start 开始的 ID,闭区间
- end 结束的 ID,闭区间
- COUNT 限制返回的数量
比如要返回 mystream 1576750346024-0 和 1576750348981-0 之间的数据,可以输入:
1 | XRANGE mystream 1576750346024-0 1576750348981-0 |
如果要返回所有的数据可以输入:
1 | XRANGE mystream - + |
XREVRANGE 命令
XREVRANGE 和 XRANGE 基本类似,但是 XREVRANGE 是将流的顺序逆转输出。这里不需要关注太多,不过要注意的是范围参数也和 XRANGE 相反 + 在前, - 在后, 如 :XREVRANGE mystream + -
其中 - 代表 0-0 的ID, + 代表 18446744073709551615-18446744073709551615 的 ID。
XDEL 命令
XDEL 用于从 stream 中删除删除指定 ID 的记录,基本用法如下:
1 | XDEL key ID [...] |
ID 可以同时指定 1 到多个。返回值是删除的数量。
需要注意的是,删除并不是真正立刻就删除数据,只是给这条数据打了一个删除标签,当1个 macro-node 中所有数据都被删除时,才会将这个 macro-node 删除掉,数据也就随之真正删除。大量删除操作会引发内存碎片化情况的出现(性能不会受到影响),(在将来的Redis版本中,如果给定的宏节点达到给定数量的已删除条目,我们可能会触发节点垃圾回收。)
举例: 删除 id 为 0-0 的数据 XDEL mystream 0-0
XTRIM 命令
XTRIM 命令用于裁剪 stream 的长度,基本用法如下:
1 | XTRIM key MAXLEN [~] count |
返回结果是裁剪掉的数量。
使用的时候,需要指定期望裁剪后的最大长度,使用 MAXLEN 关键词来指定,比如期望裁剪后的最大长度为1000:
1 | XTRIM key MAXLEN 1000 |
注意:这里说的是裁剪后的最大长度,如果 stream 本身没有达到 MAXLEN 的值,那么裁剪后的 stream 的长度还是其真实大小,即 XLEN key 所看到的结果。
本示例中包含了 ~,这个代表裁剪的时候近似的进行裁剪,可以多出 MAXLEN 几十个,但是不能少于 MAXLEN。
如: 执行 XTRIM mystream MAXLEN ~ 1000 后,查看长度 XLEN mystream 结果可能是大于1000的。
因为条目是在包含多个条目的宏节点中组织的,这些条目可以通过一次释放释放,所以可以在极短的时间内完成。
消费组
redis 不仅提供了上面的基本输入输出功能,还提供了消费组的功能。如果你用过 kafka 或者其他类似的 MQ 组件的话,可能会比较熟悉。如果不熟悉也没关系,简单介绍一下 组 的概念。
假如有2台服务器 A 和 B,部署了相同的服务,都可以读取 redis stream。
首先我们考虑直接使用 XREAD 会有什么问题?毫无疑问,2台都会收到一模一样的数据。如果这些数据确实需要扩散到每一台(术语的话叫 广播模式),那么这样操作是没有问题的,比如发送一条更新缓存的消息,每台服务都需要更新,那么这个场景就很适合广播模式。
但是假如这 2 台服务器是订单服务,还是使用 XREAD 的话,就会产生2条一样的订单,2台服务器原本是为了负载用的,现在却干了同样的事情,有点浪费资源;另外因为都接收到了一样的消息,业务上还得处理更复杂的去重工作。
这种情况下呢,消费组就可以派上用场了。
一个消费组(group)内允许有多个消费者(consumer)(上面的直接执行 XREAD 指令的都是消费者),但是1条消息只会投递到其中一个 consumer上,也就是每个 consumer 都会收到不同的消息。(这种模式术语叫做 集群模式)
下面就针对 redis stream 的消费组做一下简单介绍。
XGROUP 命令
XGROUP 支持创建和销毁组,也支持管理consumer。这个子命令还是略微有点多的,我们分开解释:
创建分组
基本格式:
1 | XGROUP CREATE key consumer-group-name ID [MKSTREAM] |
- key stream 的名字
- consumer-group-name 要创建分组的名字
- ID 开始消费的偏移量,过滤条件,只有该 ID 之后的数据才会进入到该组并且可以被consumer消费
- MKSTREAM 可选选项,默认不加的话,如果指定的 stream 不存在会返回错误,加上之后不存在则会自动创建 stream
下面进行实战讲解:
创建一个接收最新消息的组,注意 最后的 ID 是 $,consumer 只能接收新的消息。
1 | XGROUP CREATE mystream group-a $ |
创建一个接收所有消息的组,包含已经存在的消息,注意 最后的 ID 是 0,,consumer 可以消费已经存在的消息。
1 | XGROUP CREATE mystream group-b 0 |
注意 分组不允许重复创建,如果分组已经存在,则会报错:
(error) BUSYGROUP Consumer Group name already exists
删除分组
基本格式:
1 | XGROUP DESTROY key consumer-group-name |
比如要删除上面创建的 group-a 分组,可以执行 XGROUP DESTROY mystream group-a
注意 执行该指令会删除所有分组相关信息,包括 group 和 consumer 信息。
输入 XGROUP HELP 可以打印帮助信息。
XREADGROUP 命令
XREADGROUP 是专门用于读取分组消息的命令。
基本格式:
1 | XREADGROUP GROUP group-name [COUNT count] [BLOCK milliseconds] [NOACK] STREAMS key [key ...] ID [ID...] |
这个格式跟 XREAD 基本一样,只不过增加了 GROUP。
比如要读取 mystream 最新(没有投递给其他consumer)的消息,可以使用下面的命令,这也是最常用的形式:
1 | XREADGROUP GROUP group-a consumer-1 STREAMS mystream > |
注意这里面有个特殊的符号 >,在这里也是一个 ID 的表现形式,意思是说读取没有被其他消费者消费的消息(也就是最新的消息)。
如果要增加读取数量和阻塞读取,可以使用下面的命令:
1 | XREADGROUP GROUP group-a consumer-1 COUNT 10 BLOCK 10000 STREAMS mystream > |
注意 STREAMS mystream > 必须放在 BLOCK 和 COUNT 的后面。
如果指定 NOACK 参数,则说明该条消息不需要进行ack ,至于 ack ,下面会提到。
XACK
基本格式:
1 | XACK key group-name ID [ID ...] |
上面介绍了 XREADGROUP 的使用。当使用 XREADGROUP 命令(不指定 NOACK 参数)读取消息后,消息就会进入到该 stream 的未确认队列(pending entries list (PEL))。进入到 PEL 的消息是可以被重复消费的,只需要将 ID 由 > 替换为任意合法的ID即可,比如 0,则可以将该 stream 的消息再消费一次。
举例:
1 | XREADGROUP GROUP group-a consumer-1 count 10 block 100000 STREAMS mystream > |
另一个终端的 redis-cli 中输入
1 | XADD mystream * a 1 |
则上一个终端会打印出刚才添加的消息。
如果再次执行 XREADGROUP GROUP group-a consumer-1 count 10 block 100000 STREAMS mystream > 则会一直卡在那里,因为没有新的消息流入,需要等待100s才会超时。
如果我们输入
1 | XREADGROUP GROUP group-a consumer-1 count 10 block 100000 STREAMS mystream 0 |
终端立即打印出了内容,这就是因为这条消息再 PEL 中,在被 ACK 之前都是可以被重复消费的。
为了能够让这条消息从 PEL 中删除,则需要执行 ACK 命令:
1 | XACK mystream group-a 1576768897319-0 |
会打印ack的数量。
现在我们再次执行 XREADGROUP GROUP group-a consumer-1 count 10 block 100000 STREAMS mystream 0 会发现输出:
1 | 1) 1) "mystream" |
没有可以消费的消息了。
细心朋友可能会发现,既然没有消息,为什么没有进入阻塞,立马就返回结果了?这个地方,官方也明确说了,如果 ID 不是 >,那么 BLOCK 和 NOACK 是不起作用的,原文如下:
Any other ID, that is, 0 or any other valid ID or incomplete ID (just the millisecond time part), will have the effect of returning entries that are pending for the consumer sending the command with IDs greater than the one provided. So basically if the ID is not >, then the command will just let the client access its pending entries: messages delivered to it, but not yet acknowledged. Note that in this case, both BLOCK and NOACK are ignored.
XPENDING
基本格式:
XPENDING key group [start end count] [consumer]
XPENDING 可以查看为 ack 的消息情况。
先创造一点数据,并读取:
1 | XADD mystream * a 1 |
查看 pending 概要信息
1 | XPENDING mystream group-a |
输出:
1 | 1) (integer) 6 # pending 消息总数量 |
查看详细信息,需要指定 开始和结束的 ID,可以使用 - 最小 和 + 最大,数量; 也可以指定 consumer 名字,只查看这一个consumer的信息,这个是可选的。
1 | XPENDING mystream group-a - + 1 consumer:1 |
输出:
1 | 1) 1) "1576770674583-0" # 消息ID |
XINFO 命令
上面介绍了写入,读取,分组等功能,那有什么办法能看到 stream 或者 group 的信息么?XINFO 就排上用场了。
基本格式:
1 | XINFO [CONSUMERS key groupname] [GROUPS key] [STREAM key] [HELP] |
输入 XINFO HELP 可以查看帮助。
查看 stream 信息
比如查看 mystream 的信息
1 | XINFO STREAM mystream |
会打印出如下信息(可能和你的输出略微有出入),# 后面是我加的注释
1 | 1) "length" |
stream 的 group 信息
基本格式:
1 | XINFO GROUPS key |
比如要查看 mystream 的group信息:
1 | XINFO GROUPS mystream |
输出:
1 | 1) 1) "name" |
查看 group 的 consumer 信息
基本格式:
1 | XINFO CONSUMERS key group-name |
比如要查看 mystream 的 group-a 的 consumer的信息:
1 | XINFO CONSUMERS mystream group-a |
输出:
1 | 1) 1) "name" |
XCLAIM 命令
基本格式:
XCLAIM key group consumer min-idle-time ID [ID …] [IDLE ms] [TIME ms-unix-time] [RETRYCOUNT count] [FORCE] [JUSTID]
注意 一般不太常用,作为了解就可以了。
这条指令是用来转义 consumer pending 消息的。当一个 consumer 意外终止的时候,其产生的 pending(未进行ack)的消息就会始终得不到确认,并且也不能被其他消费者再次消费,那么就可以使用这个命令这些处于 pending 状态的消息转移到另一个 consumer 的 PEL 中,严格来说是将符合条件的 ID 的消息转移到指定 consumer 的 PEL中。下面使用一个例子来说明它是怎么工作的:
- 创建一个新的 stream
s:test,并添加2条消息
1 | XADD s:test * a 1 |
创建一个消费组,注意这里的 ID 是从 0开始,也就是这个组要消费所有的消息
1
XGROUP CREATE s:test g:test 0
使用 consumer:1 消费最新的消息
1
XREADGROUP GROUP g:test consumer:1 STREAMS s:test >
输出:
1
2
3
4
5
6
71) 1) "s:test"
2) 1) 1) "1576805524932-0"
2) 1) "a"
2) "1"
2) 1) "1576805529738-0"
2) 1) "a"
2) "2"使用 consumer:2 消费
1
XREADGROUP GROUP g:test consumer:2 STREAMS s:test >
因为已经被 consumer:1 消费掉了,所以只输出一个
(nil)表示没有数据。使用 consumer:1 重复消费
1
XREADGROUP GROUP g:test consumer:1 STREAMS s:test 0
还是可以读取到之前的消息:
1
2
3
4
5
6
71) 1) "s:test"
2) 1) 1) "1576805524932-0"
2) 1) "a"
2) "1"
2) 1) "1576805529738-0"
2) 1) "a"
2) "2"再来使用 consuer:2 来重复消费:
1
XREADGROUP GROUP g:test consumer:2 STREAMS s:test 0
会打印:
1
21) 1) "s:test"
2) (empty list or set)表示 consumer:2 中 没有可以重复消费的消息,也即是 PEL 中没有消息。
为了确认上面的事实,我们使用 XINFO 查看 consumer 的信息:
1 | XINFO CONSUMERS s:test g:test |
输出:
1 | 1) 1) "name" |
假如现在 consumer:1 不再使用了,或者就是想将 consumer:1 的 pending 数据转移到 consumer:2 中,就得使用 XCLAM:
1 | XCLAIM s:test g:test consumer:2 10000 1576805524932-0 JUSTID |
这条语句意思是,如果 1576805524932-0 空闲超过10s,则把 1576805524932-0 这条消息转移到 consumer:2 的 pending 中,前提是转移的时候这条消息没有被删除也没有被ACK。JUSTID 是声明只返回转移成功的 ID 号,不打印其具体内容。
输出:1) "1576805524932-0"
查看 consumer 信息 XINFO CONSUMERS s:test g:test :
输出:
1 | 1) 1) "name" |
注意 XCLAIM 会重置 consumer 的 IDLE 时间,如果想自定义可以使用参数 IDLE:
1 | XCLAIM s:test g:test consumer:2 10000 1576805524932-0 IDLE 100000 JUSTID |
当然还有几个其他参数,不太常用,暂时不详细介绍了
- TIME 跟 IDLE 差不多
- RETRYCOUNT 跟消息投递次数有关
- FORCE 强制转移(不属于本组但是属于这个stream)的消息
应用场景
总的来说,redis stream 还是提供了比较强大的功能和灵活性。但是由于其是基于内存的,在实际使用的场景中还是要仔细考虑的。
以下场景可以尝试使用:
- 对数据丢失有一定容忍性,因为是基于内存的,可能存在宕机,内存的消息就丢失了,虽然有持久化保证,但是并不是实时写入到磁盘的,所以还是会存在丢数据的风险
- 实时处理消息,不能够堆积数据。 还是因为是内存的问题,如果消息堆积非常多,就会导致 redis 内存膨胀,所以要实时(或者及时)处理消息,并将不需要的消息删除。
优点
- 轻量
- 高效(尚未进行压测)
缺点
- 实际使用略微复杂,需要手动删除不需要的(消费过的)数据
- 存在数据丢失的风险
- 大量消息堆积可能导致 redis 内存使用率过高宕机
所以大家如果有更高要求的,可以选择 RocketMQ RabbitMQ 或者 Kafka 等消息队列中间件。
macro nodes
为了提高内存效率,stream 由 macro-node(宏节点) 组成 维基英文 radix tree(维基中文 基数树)。
使用 XINFO STREAM key 可以查看 radix-tree 相关信息,比如查看我们的 mystream :
1 | XINFO STREAM mystream |
输出:
1 | 1) "length" |
其中的 radix-tree-keys 和 radix-tree-nodes 就是 nodes 的信息。
这块内容我也没了解过,所以这里就不做过多解释了。