JAVA简单数据同步框架
JAVA 简单数据同步(传输)框架
为了保持代码样式和格式,所有代码使用了图片;使用到的相关代码见文末
背景
A服务(称为上游服务)推送了数据过来后,需要服务转发数据给B,C,D(称为下游服务)。上游服务发送成功后就不关心这个数据了,需要本服务负责将这些数据安全的转发给下游服务。
但是下游服务中的任一个任何时刻都有可能出现问题,比如网络不通,服务停机维护等。所以需要本服务在提供转发数据的同时,尽可能减少其他服务的影响(B停机不影响C和D的转发),需要并行分发,同时提供重试机制。
需要考虑的问题
在介绍具体方案前,先考虑下这个场景需要考虑的问题
主要为以下2条:
- 数据分发 ,状态同步
- 重试机制
数据分发,状态同步
同一条源数据(待同步数据)需要能够分发给B、C和D。分发的过程需要并发进行,不能相互影响;由于分发任务相互独立,分发的进度也就基本上是不一致的,可能 B 已经分发到了第10条,C 分发到了第20条,D 才分发到第2条,那么每个任务的消费记录id需要分别记录。
重试机制
因为是分发给下游其他服务,不可避免的会遇到下游服务网络或者维护等情况,这种情形下,当前这一条数据分发就会失败,如果不提供重试机制,这条数据在这个任务中就会丢失。
重试机制应该根据业务设定,某些场景下需要重试,比如网络问题;某些场景下应该停止重试,比如数据格式本身错误,再怎么重试都是错误的,应该忽略这一条数据
方案
- 针对具体业务自己实现
- 消息队列(RabbitMQ,RocketMQ,Kakfa等)
自己实现
该方法只有1个任务的时候确实是最简单的,不需要引入什么框架,可能只需要1个数据库即可。大概的伪代码:

现在需要同步的任务是3个,这样的代码需要重复写3遍;如果后面又来几个新任务,又得重复几次,而且维护起来也麻烦。
使用消息队列
使用MQ(消息队列)的方式如下:
将源数据发送到mq
每个任务作为独立的consumer(消费者)去拉取消息
任务成功后commit,不成功则一直循环重试
常用的消息队列有:
Kafka
RabbitMQ
RocketMQ
Redis(list或者stream)
使用专业的消息队列,其实更有保障,但也增加了系统复杂性,需要引入一个单独的组件。如果系统中已经存在这些组件,其实还是建议直接使用MQ的。
JDS(JAVA Data Sync)框架的诞生
其实是我系统中有用到MongoDB,不想再单独引入一个MQ组件,增加系统的运维和部署成本。在进行了上面简单的一个任务编码后,将其共有的逻辑部分(分发和重试)进行了抽象,于是就有了现在这个项目,只不过现在只是实现了MongoDB的支持。
底层数据存储支持:
理论上,所有能够存储数据的组件都可以被JDS拿来作为底层数据存储层
- mongodb (已完成)
- mysql
- redis
- elasticsearch
- kafka
- rabbitmq
- zookeeper
- … 需要自行实现api接口
项目地址
项目源码存放在gitee上,https://gitee.com/sdvdxl/jds
使用方式
现在还是snapshot版本,最新版是 1.0.1-SNAPSHOT,需要加入snapshot仓库
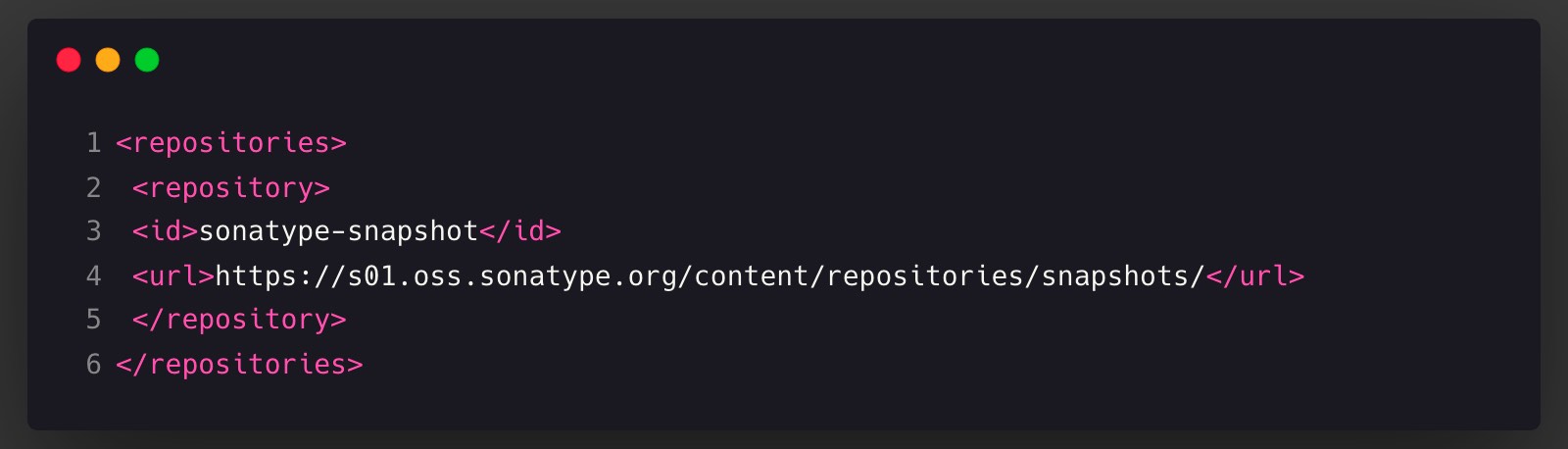
添加依赖
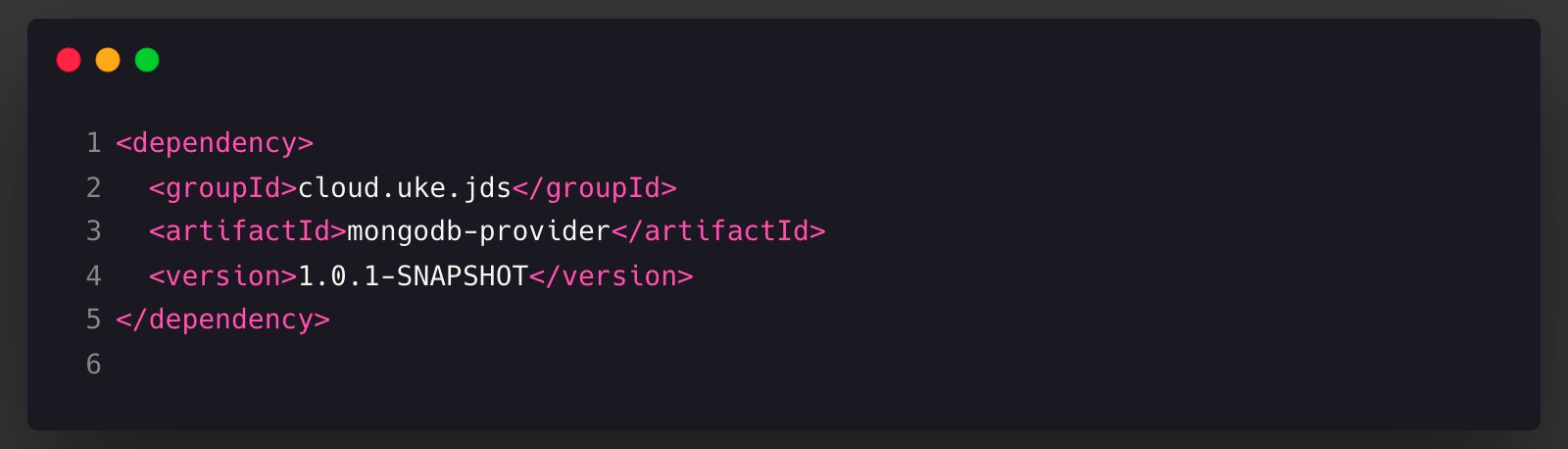
注意 该项目存储层mongodb-provider使用了spring-data-mongo模块,需要使用到 MongoTemplate。
核心类是 DataSync,该类提供了以下方法来操作数据同步任务
- start 启动数据同步
- pause 暂停数据同步
- stop 停止数据同步(此实例无法再次使用,需要重新实例化)
- veryDangerOperationCleanAllData 删除 src 相关的原始数据,并删除src和target相关的同步状态,注意这个是非常危险的操作,数据不可恢复,所以弄了个这么长的名字以此引起你的注意
- putData 同步记录新增的数据进行持久化
简单示例
需要本地安装mongo,如果没有可以使用docker命令快速启动一个

用例代码:
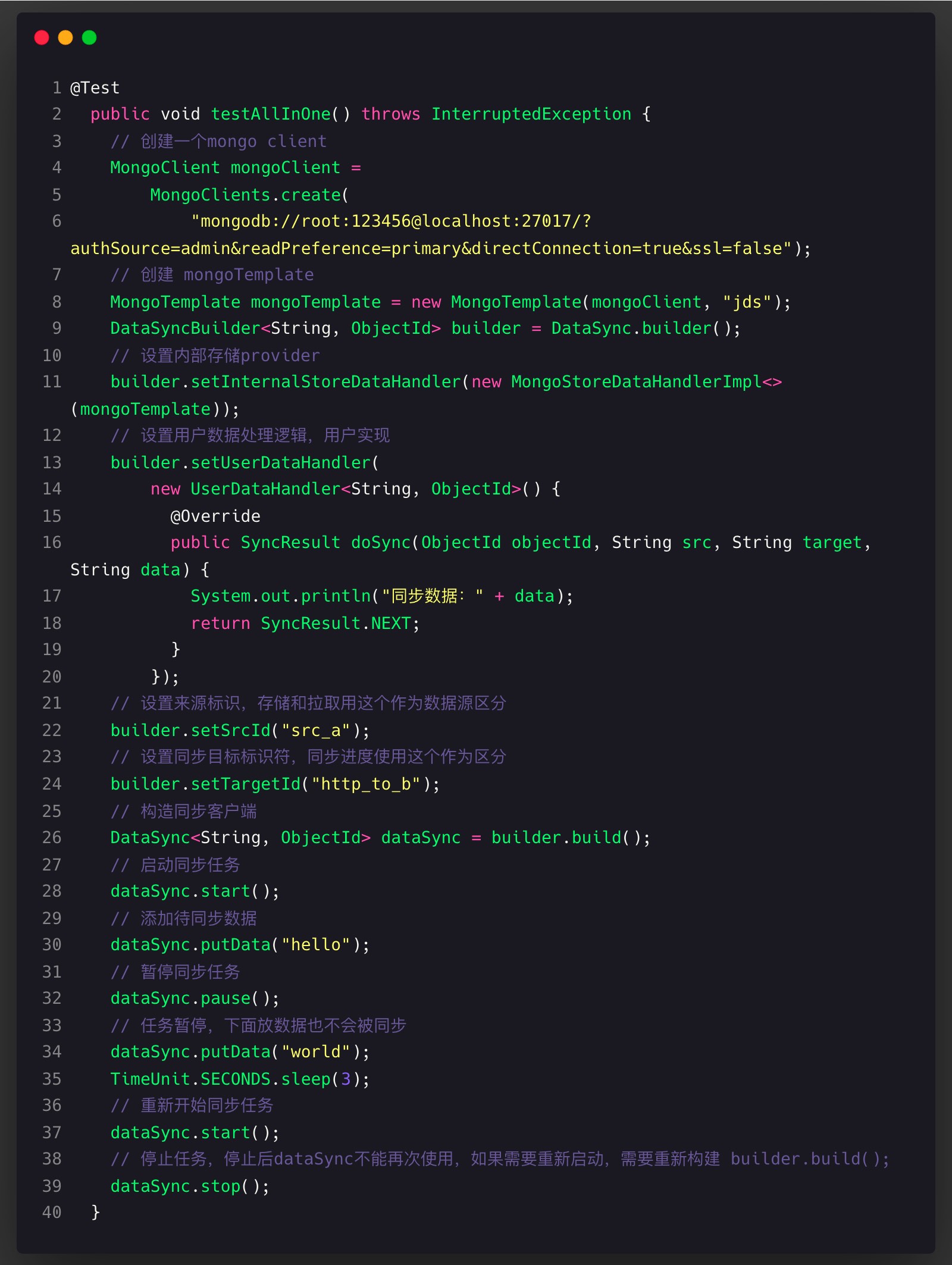
扩展
数据库方面同步框架或者软件有:
TapData https://tapdata.net/
代码
总结
数据同步任务需要考虑状态隔离和错误重试
jds(本框架) 只实现了 MongoDB 作为存储层
jds 现在没有经过大规模测试,只适合简单任务(非分布式,集群)使用
预告
下次介绍jds实现方式